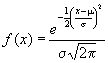Las medidas de dispersión son números que indican si una variable se mueve mucho, poco, más o menos que otra. La razón de ser de este tipo de medidas es conocer de manera resumida una característica de la variable estudiada. En este sentido, deben acompañar a las medidas de tendencia central. Juntas, ofrecen información de un sólo vistazo que luego podremos utilizar para comparar y, si fuera preciso, tomar decisiones.
Principales medidas de dispersión
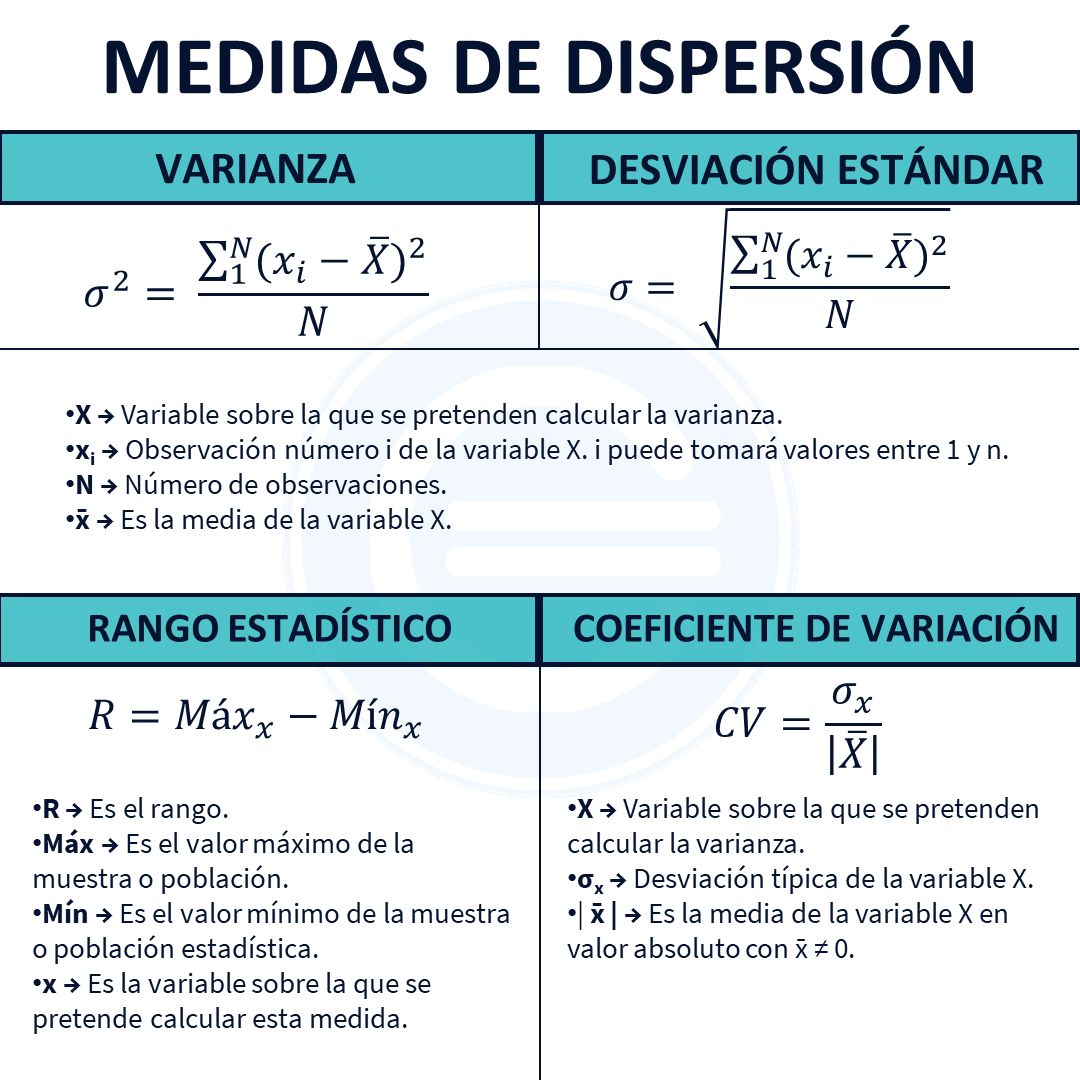
Las medidas de dispersión más conocidas son: el rango, la varianza, la desviación típica y el coeficiente de variación (no confundir con coeficiente de determinación). A continuación veremos estas cuatro medidas.
Rango
El rango es un valor numérico que indica la diferencia entre el valor máximo y el mínimo de una población o muestra estadística. Su fórmula es:
Donde:
R→ Es el rango.
Máx→ Es el valor máximo de la muestra o población.
Mín → Es el valor mínimo de la muestra o población estadística.
x→ Es la variable sobre la que se pretende calcular esta medida.
Varianza
La varianza es una medida de dispersión que representa la variabilidad de una serie de datos respecto a su media. Formalmente se calcula como la suma de los residuos al cuadrado divididos entre el total de observaciones. Su fórmula es la siguiente:
X→ Variable sobre la que se pretenden calcular la varianza
xi→ Observación número i de la variable X. i puede tomará valores entre 1 y n.
N → Número de observaciones.
x̄ → Es la media de la variable X.
A continuación se muestra una imagen que resume las fórmulas anteriores:
MEDIDAS DE FORMA
Las medidas de forma son aquellas que nos muestran si una distribución de frecuencia tiene características especiales como simetría, asimetría, nivel de concentración de datos y nivel de apuntamiento que la clasifiquen en un tipo particular de distribución.
Para analizar estos asepctos recurriremos a dos tipos de medida:
Coeficiente de asimetria de Fischer.
Coeficiente de curtosis a apuntamiento de Fisher.
COEFIENTE DE ASIMETRÍA DE FISHER
Una distribución es simétrica cuando al trazar una vertical, en el diagrama de barras o histograma de una variable, según sea esta discreta o continua, por el valor de la media, esta vertical se transforma en eje de simetría y entonces decimos que la distribución es simétrica. En caso contrario, dicha distribución será asimétrica o diremos que presenta asimetría.
La asimetría puede ser de dos tipos:
Asimétrica por la derecha.
Asimétrica por la izquierda.
COEFIENTE DE CURTOSIS O APUNTAMIENTO DE FISHER
La otra medida de forma que vamos a considerar es el apuntamiento, al igual que con la simetría hemos de tomar una referencia para ver si la distribución de los datos es apuntada o no. La referencia citada es la distribución normal, y así distinguiremos tres casos:
Leptocúrtica, si la distribución es más picuda que la normal,
Mesocúrtica, si la distribución es igual a la normal, y
Platicúrtica, si la distribución es más aplastada que la normal
PARA QUE COMPRENDAS MEJOR EL TEMA TE DEJO ESTE VIDEO
Promedio o media La medida de tendencia central más conocida y utilizada es la media aritmética o promedio aritmético. Se representa por la letra griega µ cuando se trata del promedio del universo o población y por Ȳ (léase Y barra) cuando se trata del promedio de la muestra. Es importante destacar que µ es una cantidad fija mientras que el promedio de la muestra es variable puesto que diferentes muestras extraídas de la misma población tienden a tener diferentes medias. La media se expresa en la misma unidad que los datos originales: centímetros, horas, gramos, etc.
Si una muestra tiene cuatro observaciones: 3, 5, 2 y 2, por definición el estadígrafo será:
Estos cálculos se pueden simbolizar:
Donde Y1 es el valor de la variable en la primera observación, Y2 es el valor de la segunda observación y así sucesivamente. En general, con “n” observaciones, Yi representa el valor de la i-ésima observación. En este caso el promedio está dado por
De aquí se desprende la fórmula definitiva del promedio:
Desviaciones: Se define como la desviación de un dato a la diferencia entre el valor del dato y la media:
Ejemplo de desviaciones:
Una propiedad interesante de la media aritmética es que la suma de las desviaciones es cero.
Mediana Otra medida de tendencia central es la mediana. La mediana es el valor de la variable que ocupa la posición central, cuando los datos se disponen en orden de magnitud. Es decir, el 50% de las observaciones tiene valores iguales o inferiores a la mediana y el otro 50% tiene valores iguales o superiores a la mediana.
Si el número de observaciones es par, la mediana corresponde al promedio de los dos valores centrales. Por ejemplo, en la muestra 3, 9, 11, 15, la mediana es (9+11)/2=10.
Moda La moda de una distribución se define como el valor de la variable que más se repite. En un polígono de frecuencia la moda corresponde al valor de la variable que está bajo el punto más alto del gráfico. Una muestra puede tener más de una moda.
Medidas de dispersión
Las medidas de dispersión entregan información sobre la variación de la variable. Pretenden resumir en un solo valor la dispersión que tiene un conjunto de datos. Las medidas de dispersión más utilizadas son: Rango de variación, Varianza, Desviación estándar, Coeficiente de variación.
Rango de variación Se define como la diferencia entre el mayor valor de la variable y el menor valor de la variable.
La mejor medida de dispersión, y la más generalizada es la varianza, o su raíz cuadrada, la desviación estándar. La varianza se representa con el símbolo σ² (sigma cuadrado) para el universo o población y con el símbolo s2 (s cuadrado), cuando se trata de la muestra. La desviación estándar, que es la raíz cuadrada de la varianza, se representa por σ (sigma) cuando pertenece al universo o población y por “s”, cuando pertenece a la muestra. σ² y σ son parámetros, constantes para una población particular; s2 y s son estadígrafos, valores que cambian de muestra en muestra dentro de una misma población. La varianza se expresa en unidades de variable al cuadrado y la desviación estándar simplemente en unidades de variable.
Fórmulas Donde µ es el promedio de la población.
Donde Ȳ es el promedio de la muestra.
Consideremos a modo de ejemplo una muestra de 4 observaciones
Según la fórmula el promedio calculado es 7, veamos ahora el cálculo de las medidas de dispersión:
s2 = 34 / 3 = 11,33 Varianza de la muestra
La desviación estándar de la muestra (s) será la raíz cuadrada de 11,33 = 3,4.
Interpretación de la varianza (válida también para la desviación estándar): un alto valor de la varianza indica que los datos están alejados del promedio. Es difícil hacer una interpretación de la varianza teniendo un solo valor de ella. La situación es más clara si se comparan las varianzas de dos muestras, por ejemplo varianza de la muestra igual 18 y varianza de la muestra b igual 25. En este caso diremos que los datos de la muestra b tienen mayor dispersión que los datos de la muestra a. esto significa que en la muestra a los datos están más cerca del promedio y en cambio en la muestra b los datos están más alejados del promedio.
Coeficiente de variación Es una medida de la dispersión relativa de los datos. Se define como la desviación estándar de la muestra expresada como porcentaje de la media muestral.
Es de particular utilidad para comparar la dispersión entre variables con distintas unidades de medida. Esto porque el coeficiente de variación, a diferencia de la desviación estándar, es independiente de la unidad de medida de la variable de estudio.
Los datos numéricos obtenidos en un estudio estadístico pueden presentarse de forma visual a través de gráficas estadísticas, lo que hace que sean más fácilmente comprensibles.
Hay muchos tipos de gráficas, las más comunes son:
Diagrama de barras
Diagrama de líneas (polígono de frecuencias).
Diagrama de sectores
Hacer gráficos es bastante sencillo si tenemos los datos organizados en tablas de frecuencias.
Hemos encuestado a 50 estudiantes del colegio sobre su deporte favorito:
Los resultados los hemos organizado en esta tabla de frecuencias.
Hemos representado gráficamente mediante un diagrama de barras para obtener una visualización general de los resultados de nuestra encuesta.
El proceso para construir un diagrama de barras es muy sencillo.
Se construyen dos ejes.
En el eje horizontal, o eje de abscisas, se representan los datos o modalidades obtenidos. En nuestro caso: baloncesto, fútbol, balonmano, etc.
En el eje vertical, eje de ordenadas, se representan con números las frecuencias de cada dato o modalidad.
Sobre el eje horizontal se levantan barras o rectángulos de igual base hasta hasta la altura del valor numérico de la frecuencia de cada modalidad. En nuestro caso: baloncesto hasta 12, fútbol hasta 8, balonmano hasta 10, etc.
El proceso es muy similar al empleado en los gráficos de barras:
En el eje horizontal, abscisas, se representan los datos.
En el eje vertical, ordenadas, se representan los valores de cada dato si la variable es cuantitativa o la frecuencia de cada dato si la variable es cualitativa.
Se trazan puntos o marcas que representan esos datos y se unen con segmentos.
En este ejemplo hemos tomado las temperaturas mínimas durante una semana de la estación meteorológica del colegio y lo hemos representado como una línea poligonal que nos indica muy bien las variaciones.
CONCLUSION: LO QUE PODEMOS CONCLUIR DE ESTE TEMA ES QUE LA MEDIA ARITMETICA ES EL PROMEDIO, LA MEDIA ES EL DATO QUE QUEDA EN MEDIO Y LA MODA ES EL QUE MAS SE REPITE.
AQUI TE DEJO UN VIDEO PARA QUE COMPRENDAS MAS EL TEMA
Lo primero que haremos será explicar qué es una escala de medición. Su definición consiste en un proceso de comparación cuantitativa o cualitativa entre dos o más elementos. Esta herramienta utiliza símbolos y números para determinar la cantidad de veces que aparece un determinado patrón en el conjunto de elementos.
Por otro lado, cabe destacar que un elemento puede ser cualquier objeto capaz de ser medible. Por lo general los elementos de una escala de medición están conformados por propiedades o características que se entrecruzan a partir de la medición de indicadores. Estos indicadores tendrán que ver con los reactivos o determinantes del comportamiento del objeto de estudio.
Tipos de escalas de medición
Ahora que ya conoces algunas características principales de las escalas de medición pasemos a desarrollar los distintos tipos existentes. Los mismos pueden variar de acuerdo a las propiedades o características de los datos a comparar. Existen cuatro escalas de medición en estadística, a saber: ordinal, nominal, de razón y de intervalo.
Escala ordinal
En primer lugar, tenemos al tipo de escala ordinal. La misma plantea un orden de los elementos según su jerarquía o calidad. Por ejemplo, si medimos la calidad del contenido de cinco libros distintos que hablan de una misma temática, podemos ordenarlos del 1 al 5. El 1 puede ser el libro con mejor calidad y relevancia y el 5 el de peor jerarquía. De esta manera, tendremos una escala en cuanto al orden de la variable “calidad”.
Nominal
Siguiendo con los tipos de escala de medición nos encontramos con la escala nominal. Esta no tiene que ver con el ordenamiento, sino que, se concentra en clasificar los elementos observados. Siguiendo el ejemplo anterior, la escala nominal podría definir el género de la mayoría de los votantes en cuanto a si un libro es mejor que otro. En este sentido, si la votación reúne un número de 50 personas, la escala nominal definirá cuántos de esos votantes fueron mujeres y cuántos hombres.
La principal finalidad de esta escala de medición es determinar y comparar las características nominales o de “etiqueta” de un determinado resultado.
De intervalo
La escala de intervalo tiene algunas propiedades similares a las de la escala ordinal en cuanto a su orden de jerarquía. Además de esto, la escala de intervalo añade una separación entre las variables de acuerdo a su sentido.
Un ejemplo de este tipo de escala puede ser la Net Promote Score, una herramienta utilizada por las empresas para medir la satisfacción de sus clientes. Básicamente consiste en una pregunta relacionada a la satisfacción con una escala del 1 al 10. De esta manera, la escala se confecciona de acuerdo a los resultados de la encuesta para agruparse de la siguiente manera:
Del 1 al 6 = clientes poco satisfechos.
7 a 8 = clientes moderadamente satisfechos.
9 a10 = clientes satisfechos que seguramente recomendarán los servicios o productos de la empresa.
Como puedes ver, la escala de medición de intervalo plantea justamente eso, intervalos entre un número y otro de medición.
De razón
Por último, tenemos el tipo de escala de medición de razón. Con ella podemos medir la razón de un determinado fenómeno o suceso. Por ejemplo, para medir la calidad de un libro, se puede hacer una escala de razón en función del número de venta de los libros comparados. En este caso, la escala estará encabezada por el libro con más ventas y finalizará con el que se haya vendido menos.
Variables en las escalas de medición
Antes explicamos las características y tipos de escala de medición, y para ello nombramos varias veces el concepto de variable. Con respecto a las variables podemos decir que las mismas se dividen según distintos criterios relacionados a las características y valores. A continuación te lo explicaremos mejor definiendo y diferenciando las variables cualitativas y cuantitativas.
Cualitativas
Este tipo de variables son aquellas que describen las cualidades o los atributos de un objeto o persona sin utilizar números. Un ejemplo de este tipo de variable en una escala de medición puede ser el género de una persona o el color de un auto, entre otros ejemplos.
Cuantitativas
Por otro lado tenemos las variables cuantitativas. Estas hacen uso de valores numéricos para definir los datos obtenidos. Son comúnmente utilizadas en las escalas de medición de intervalo o de razón. Este tipo de variable puede tomar como dato numérico el peso de una persona para compararlo con el peso medio de una misma población, sólo por dar un ejemplo.
POBLACION ESTADISTICA
Una población estadística es el total de individuos o conjunto de ellos que presentan o podrían presentar el rasgo característico que se desea estudiar.
Empezaremos por la palabra población. ¿En qué piensas cuando lees o escuchas la palabra población? Muy probablemente en un número de personas. Por ejemplo, la población de Argentina, la población de Chile, la población de Nueva York o la población mundial. Y dirás, ¿qué tiene que ver la población con la estadística? Pues tiene que ver mucho. Todo se remonta a los orígenes de la palabra estadística.
Con esto en mente, seguiremos la siguiente secuencia para entender el concepto: origen de la palabra, principales tipos de población y un ejemplo de población estadística.
Tipos de población estadística
Dentro de las poblaciones estadísticas, fundamentalemente dos tipos de poblaciones:
Población estadística finita: Es aquella en la que el número de valores que la componen tiene un fin. Por ejemplo, la población estadística que nos indica la cantidad de árboles de una ciudad es finita. Es cierto que puede variar con el tiempo, pero en un instante determinado es finita, tiene fin.
Población estadística infinita: Se trata de aquella población que no tiene fin. Por ejemplo, el número de planetas que existen en el universo. Aunque puede que sea finito, el número es tan grande y desconocido que estadísticamente se asume como infinito.
Adicionalmente, dentro de esta gran clasificación, existen otros tipos de poblaciones. Poblaciones según la distribución de los datos, según el tipo de dato (cualitativo o cuantitativo), etc.
MUESTRA ESTADISTICA
Una muestra estadística es un subconjunto de datos perteneciente a una población de datos. Estadísticamente hablando, debe estar constituido por un cierto número de observaciones que representen adecuadamente el total de los datos.
Tipos de muestra estadística
A continuación te explicamos los diferentes tipos de muestra estadística que hay. Antes de nada cabe destacar que se pueden dividir en dos grandes grupos, muestra probabilística y muestra no probabilística:
Muestra probabilística: En este tipo de muestras todos los sujetos disponibles tienen las mismas probabilidades de ser incluidos.
Muestra aleatoria simple: Es un conjunto de variables aleatorias independientes e idénticamente distribuidas, obtenidas a partir de la variable aleatoria X y que se distribuyen igual que la misma.
Muestra aleatoria sistemática: En este caso la población se enumera y se agrupa en grupos de 10 personas. Posteriormente, se selecciona a un miembro de cada grupo para elaborar la muestra.
Muestra aleatoria por conglomerados: La población se encuentra ya agrupada previamente y de estos grupos se extraen los individuos para conformar la muestra.
Muestra estratificada: En este caso la población se divide en subgrupos o estratos con base en las variables de estratificación.
Muestra no probabilística: En este tipo de selección de muestra todos los elementos no tienen la misma probabilidad de ser elegidos, ya que depende del procedimiento escogido para seleccionarlos.
Bola de nieve: En primer lugar se seleccionan a diferentes sujetos. A partir de ahí estos sujetos colaboran para encontrar a más sujetos que tengan relación con ellos.
Muestra por cuotas: La población es elegida en función a unas características determinadas.
Muestra discrecional: La selección de la población la realizan los investigadores en función a su propio criterio.
Muestra por conveniencia: Es una muestra elegida por los propios investigadores según su interés o cercanía.
CONCLUSION: Podemos concluir que una población es un conjunto de datos de personas con una característica en común y una muestra es un subconjunto de la misma población, existen diferentes tipos de poblaciones las que se pueden contar (finitas) y las que no se pueden contar (infinitas), al igual que también existen diferentes tipos de muestra
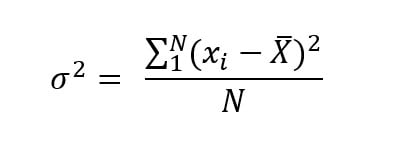
 COEFIENTE DE ASIMETRÍA DE FISHER
COEFIENTE DE ASIMETRÍA DE FISHER La otra medida de forma que vamos a considerar es el apuntamiento, al igual que con la simetría hemos de tomar una referencia para ver si la distribución de los datos es apuntada o no. La referencia citada es la distribución normal, y así distinguiremos tres casos:
La otra medida de forma que vamos a considerar es el apuntamiento, al igual que con la simetría hemos de tomar una referencia para ver si la distribución de los datos es apuntada o no. La referencia citada es la distribución normal, y así distinguiremos tres casos: