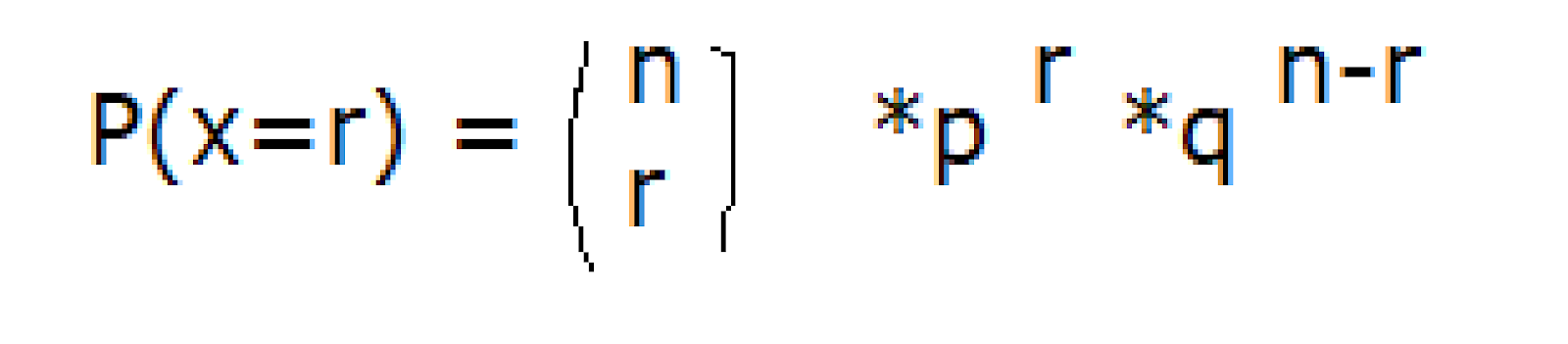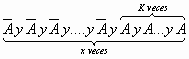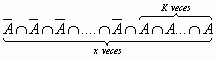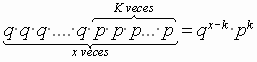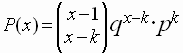DISTRIBUCION NORMAL
La distribución normal es la más importante de todas las distribuciones de probabilidad. Es una distribución de variable continua con campo de variación [-¥ ,¥ ], que queda especificada a través de dos parámetros ( que acaban siendo la media y la desviación típica de la distribución).
Una variable aleatoria continua, X, definida en [-¥ ,¥ ] seguirá una distribución normal de parámetros m y s , ( X ~ N(m ; s ) ) , si su función de densidad es :
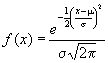 para x Î [-¥ ,¥ ]
para x Î [-¥ ,¥ ]
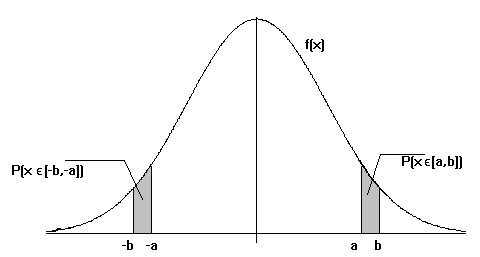
cuya representación gráfica es:
Importancia de la distribución Normal.
a) Enorme número de fenómenos que puede modelizar: Casi todas las características cuantitativas de las poblaciones muy grades tienden a aproximar su distribución a una distribución normal.
b) Muchas de las demás distribuciones de uso frecuente, tienden a distribuirse según una Normal, bajo ciertas condiciones.
c) (En virtud del teorema central del límite).Todas aquellas variables que pueden considerarse causadas por un gran número de pequeños efectos (como pueden ser los errores de medida) tienden a distribuirse según una distribución normal.
La probabilidad de cualquier intervalo se calcularía integrando la función de densidad a lo largo de ese de intervalo, pero no es necesario nunca resolver la integral pues existen tablas que nos evitan este problema.
F.G.M.: puede probarse que la función generatriz de momentos de una distribución N(m ; s ) es:
f (t) = E(etx) = e(m t + ½ s2t2)
A partir de ella es fácil comprobar como efectivamente la media de la distribución es el parámetro m y, cómo su varianza es el parámetro s .
Igualmente puede comprobarse que la distribución es simétrica y que su curtósis es nula.
Propiedad importante: "CUALQUIER TRANSFORMACIÓN LINEAL DE UNA VARIABLE ALEATORIA NORMAL TIENE TAMBIÉN UNA DISTRIBUCIÓN NORMAL DONDE LA MEDIA DE LA NUEVA VARIABLE ES LA MISMA TRANSFORMACIÓN LINEAL DE LA MEDIA DE LA ANTIGUA Y DONDE LA DESVIACIÓN TÍPICA ES LA DESVIACIÓN TÍPICA ANTIGUA MULTIPLICADA POR EL COEFICIENTE ANGULAR DE LA TRANSFORMACIÓN":
Dada una variable X ~ N(m ; s ) si la nueva variable Y es Y = a+bX
Y~ N(a+bm ; bs ) :
en efecto: la F.G.M de la distribución de X será:
E(etx) = e(m t + ½ s2t2)
y la F.G.M. de la distribución de Y será:
fy(t)= eat.fx(bt) = eat .e(m bt + ½ s2b2t2) = e((a+bm )t + (bs )2t2)
que es la F.G.M de una distribución N(a+bm ; bs ) //*q.e.d.*//
Consecuencia importante de esto es que si se tipifica una variable X / X ~ N(m ; s ) la nueva variable Z = tendrá una distribución N(0,1).
La distribución N(0,1) se conoce con el nombre de Normal tipificada o reducida y tiene una importancia teórica y práctica fundamental.Su Función de distribución está tabulada y ello nos permite calcular directamente cualquier probabilidad de cualquier intervalo de cualquier distribución normal ( X ~ N(m ; s )), sin necesidad de integrar.
En efecto: si X ~ N(m ; s ) y queremos calcular P(XÎ [a,b])==P(a£ X £ b) =
![]()
donde F es la F. de distribución de una Normal tipificada, que puede evaluarse a través de las tablas.
DISTRIBUCION UNIFORME:
La distribución o modelo uniforme puede considerarse como proveniente de un proceso de extracción aleatoria .El planteamiento radica en el hecho de que la probabilidad se distribuye uniformemente a lo largo de un intervalo . Así : dada una variable aleatoria continua, x , definida en el intervalo [a,b] de la recta real, diremos que x tiene una distribución uniforme en el intervalo [a,b] cuando su función de densidad para ![]() sea:
sea: ![]() para x Î [a,b].
para x Î [a,b].
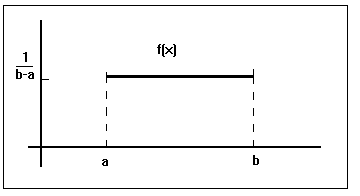
Su representación gráfica será :
De manera que la función de distribución resultará:

Su representación gráfica será :
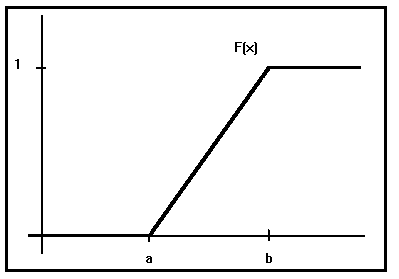
Este modelo tiene la característica siguiente : Si calculamos la probabilidad del suceso
![]()
Tendremos: ![]()
Este resultado nos lleva a la conclusión de que la probabilidad de cualquier suceso depende únicamente de la amplitud del intervalo (D X) , y no de su posición en la recta real [a , b] . Lo que viene ha demostrar el reparto uniforme de la probabilidad a lo largo de todo el campo de actuación de la variable , lo que , por otra parte, caracteriza al modelo.
En cuanto a las ratios de la distribución tendremos que la media tiene la expresión:
![]()
La varianza tendrá la siguiente expresión:
![]()
de donde ![]()
![]()
por lo que 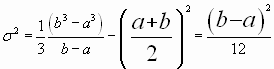
La función generatriz de momentos vendrá dada por :
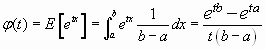
Lógicamente partiendo de esta función podríamos recalcular media y varianza gracias al teorema de los momentos
DISTRIBUCION EXPONENCIAL
A pesar de la sencillez analítica de sus funciones de definición, la distribución exponencial tiene una gran utilidad práctica ya que podemos considerarla como un modelo adecuado para la distribución de probabilidad del tiempo de espera entre dos hechos que sigan un proceso de Poisson. De hecho la distribución exponencial puede derivarse de un proceso experimental de Poisson con las mismas características que las que enunciábamos al estudiar la distribución de Poisson, pero tomando como variable aleatoria , en este caso, el tiempo que tarda en producirse un hecho
Obviamente, entonces , la variable aleatoria será continua. Por otro lado existe una relación entre el parámetro a de la distribución exponencial , que más tarde aparecerá , y el parámetro de intensidad del proceso l , esta relación es a = l
Al ser un modelo adecuado para estas situaciones tiene una gran utilidad en los siguientes casos:
· Distribución del tiempo de espera entre sucesos de un proceso de Poisson
· Distribución del tiempo que transcurre hasta que se produce un fallo, si se cumple la condición que la probabilidad de producirse un fallo en un instante no depende del tiempo transcurrido .Aplicaciones en fiabilidad y teoría de la supervivencia.
Función de densidad.
A pesar de lo dicho sobre que la distribución exponencial puede derivarse de un proceso de Poisson , vamos a definirla a partir de la especificación de su función. de densidad:
Dada una variable aleatoria X que tome valores reales no negativos {x ³ 0} diremos que tiene una distribución exponencial de parámetro a con a ³ 0, si y sólo si su función de densidad tiene la expresión: ![]()
Diremos entonces que ![]()
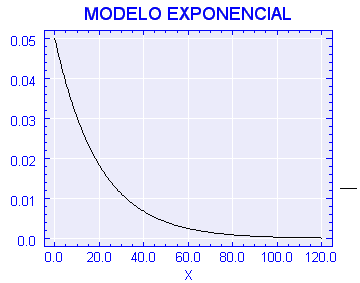
Gráficamente como ejemplo planteamos el modelo con parámetro a =0,05
En consecuencia , la función de distribución será:
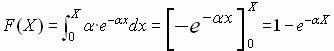
En la principal aplicación de esta distribución , que es la Teoría de la Fiabilidad, resulta más interesante que la función de distribución la llamada Función de Supervivencia o Función de Fiabilidad.
La función de Supervivencia se define cómo la probabilidad de que la variable aleatoria tome valores superiores al valor dado X:
![]()
Si el significado de la variable aleatoria es "el tiempo que transcurre hasta que se produce el fallo": la función de distribución será la probabilidad de que el fallo ocurra antes o en el instante X: y , en consecuencia la función de supervivencia será la probabilidad de que el fallo ocurra después de transcurrido el tiempo X ; por lo tanto, será la probabilidad de que el elemento, la pieza o el ser considerado "Sobreviva" al tiempo X ; de ahí el nombre.
Gráficamente, la función de distribución para un modelo exponencial de parámetro a =0,05 sería :
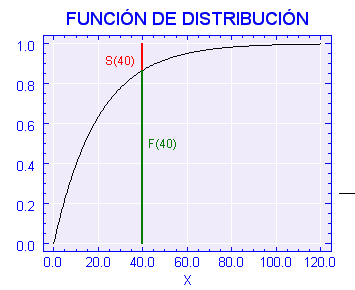
En la que se observa lo que sería la diferencia entre función de distribución y la de supervivencia
La Función Generatriz de Momentos será :
![]()
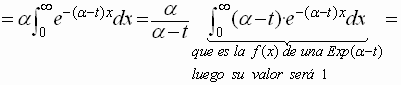
tendremos así que la F.G.M será :
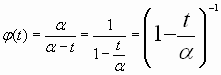
Una vez calculada la F.G.M podemos , partiendo de ella , calcular la media y la varianza
Así la media será:
![]()
![]()
En cuando a la varianza su expresión será :
![]() ya que
ya que
![]()
La mediana del modelo exponencial será aquel valor de la variable x =Me que verifica que F(Me) = ½
De manera que ![]() por lo que
por lo que ![]()
Tasa instantánea de fallo.
Dentro del marco de la teoría de la fiabilidad si un elemento tiene una distribución del tiempo para un fallo con una función de densidad f(x) , siendo x la variable tiempo para que se produzca un fallo , y con una función de supervivencia S(X) La probabilidad de que un superviviente en el instante t falle en un instante posterior t + D t será una probabilidad condicionada que vendrá dada por:
![]()
Al cociente entre esta probabilidad condicionada y la amplitud del intervalo considerado, t , se le llama tasa media de fallo en el intervalo [t , t+D t] :
![]()
Y a la tasa media de fallo en un intervalo infinitésimo es decir, al límite de la tasa media de fallo cuando D t® 0 se le llama Tasa Instantánea de Fallo (o, simplemente, tasa de fallo) en t:
![]()
![]()
La tasa de fallo es, en general, una función del tiempo, que define unívocamente la distribución.
Pues bien, puede probarse que el hecho de que la tasa de fallo sea constante es condición necesaria y suficiente para que la distribución sea exponencial y que el parámetro es, además, el valor constante de la tasa de fallo.
en efecto:
si ![]()
![]() de donde
de donde ![]() integrando esta ecuación diferencial entre 0 y x :
integrando esta ecuación diferencial entre 0 y x :
![]()
![]() de modo que la función de distribución será
de modo que la función de distribución será
![]() Función de Distribución de una Exponencial
Función de Distribución de una Exponencial
![]()
Si X tiene una distribución exponencial ![]()
de manera que ![]()
Así pues si un elemento tiene una distribución de fallos exponencial su tasa de fallos se mantiene constante a lo largo de toda la vida del elemento. La probabilidad de fallar en un instante no depende del momento de la vida del elemento en el que nos encontremos; lo que constituye la propiedad fundamental de la distribución que ahora enunciamos:
Propiedad fundamental de la distribución exponencial
La distribución exponencial no tiene memoria :
Poseer información de que el elemento que consideramos ha sobrevivido un tiempo S (hasta el momento) no modifica la probabilidad de que sobreviva t unidades de tiempo más. La probabilidad de que el elemento falle en una hora (o en un día, o en segundo) no depende del tiempo que lleve funcionando. No existen envejecimiento ni mayor probabilidad de fallos al principio del funcionamiento

Expresión que no depende , como se observa , del tiempo sobrevivido s.
CONCLUSION: Con esto podemos concluir que estas tres distribuciones describe las probabilidades de los posibles valores de una variable aleatoria continua. Una variable aleatoria continua es una variable aleatoria con un conjunto de valores posibles (conocido como el rango) que es infinito y no se puede contar.
AQUI TE DEJO UN VIDEO
PARA MEJOR COMPRENSION: